
Садржај

Извор: Кран77 / Дреамстиме.цом
Одузети:
Модели дубоког учења подучавају рачунаре да размишљају самостално, уз врло забавне и занимљиве резултате.
Дубоко учење се примењује на све више домена и индустрија. Од аутомобила без возача, играња Гоа, генерисања музике за слике, свакодневно излазе нови модели дубоког учења. Овде прелазимо неколико популарних модела дубоког учења. Научници и програмери узимају ове моделе и модификују их на нове и креативне начине. Надамо се да ће вас овај излог моћи надахнути да видите шта је могуће. (Да бисте сазнали о напретку у вештачкој интелигенцији, погледајте поглавље Да ли ће рачунари моћи да имитирају људски мозак?)
Неурални стил
Не можете побољшати своје вештине програмирања када никога није брига за квалитет софтвера.
Неурал Сторителлер

Неурал Сторителлер је модел који, када му је дата слика, може генерирати романтичну причу о слици. То је забавна играчка, а ипак можете замислити будућност и видети у ком се смеру сви ти модели вештачке интелигенције крећу.

Горња функција је "пребацивање стила" која омогућава моделу да стандардне наслове слике пребаци у стил приче из романа. Промена стила инспирисана је "Неуралним алгоритам уметничког стила".
Подаци
Постоје два главна извора података који се користе у овом моделу. МСЦОЦО је Мицрософтов скуп података који садржи око 300.000 слика, а свака слика садржи пет наслова. МСЦОЦО је једини коришћени надзирани податак, што значи да је то једини податак где су људи морали да уђу и изричито напишу титлове за сваку слику.
Једно од главних ограничења неуронске мреже за напредни пренос је то што нема меморије. Свако предвиђање независно је од претходних израчуна, као да је прво и једино предвиђање које је мрежа икада направила. Али за многе задатке, попут превођења реченице или одломка, уноси се требају састојати од секвенцијалних и међусобно повезаних података. На пример, било би тешко смислити једну реч у реченици без конуса које пружају околне речи.
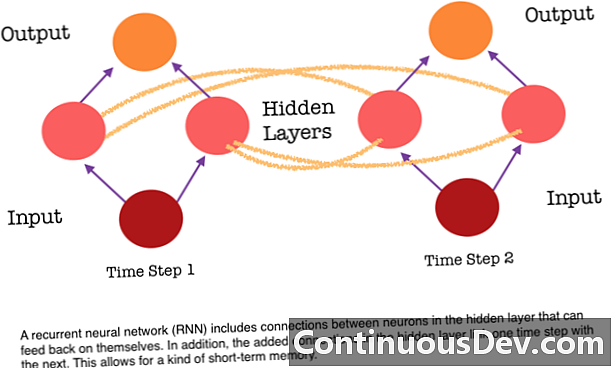
РНН-ови се разликују јер додају други скуп веза између неурона. Ове везе омогућавају да се активације неурона у скривеном слоју поново врате у себе на следећем кораку у низу. Другим речима, на сваком кораку, скривени слој прима и активацију и од слоја испод њега, али и из претходног корака у низу. Ова структура у основи даје понављајућу меморију неуронских мрежа. Дакле, за задатак откривања објеката РНН може засновати на својим претходним класификацијама паса како би утврдио да ли је тренутна слика пас.
Цхар-РНН ТЕД
Ова флексибилна структура у скривеном слоју омогућава РНН-овима да буду веома добри за језичке моделе на нивоу карактера. Цхар РНН, који је првотно створио Андреј Карпатхи, модел је који једну датотеку узима као улаз и тренира РНН како би научио да предвиди следећи знак у низу. РНН може да генерише лик по карактеру који ће личити на оригиналне податке о тренингу. Демо је обучен користећи транскрипте различитих ТЕД разговора. Напишите модел једном или више кључних речи и створиће одломак о кључним речима у гласу / стилу ТЕД разговора.
Закључак
Ови модели показују нове искораке у машинској интелигенцији који су постали могући због дубоког учења. Дубоко учење показује да можемо решити проблеме које никад пре нисмо могли да решимо, а још увек нисмо стигли до тог висоравни. Очекујте да ћете видети много узбудљивијих ствари као што су аутомобили без возача у наредних пар година као резултат иновације дубоког учења.